Why the Boring Portfolio Wins: Benchmarking Markowitz, Black-Litterman, and Rule-Based Construction
Rule-based portfolio construction doesn't win despite its simplicity — it wins because of it.
TL;DR: In a 20-year ETF benchmark, a simple rule-based allocation outperformed Markowitz and Black-Litterman in CAGR while trading less and staying aligned with client mandates. Optimization improved Sharpe ratio — but failed the production test.
For: Robo-advisor PMs · quant developers in wealth management · FinTech founders · institutional allocators
The Question Nobody Asks
Every Robo-Advisor pitch deck mentions "sophisticated portfolio optimization." Few mention what that optimization actually looks like in production. So I built all three major approaches, ran them on 20 years of real ETF data, and measured what matters: returns, costs, and whether you can explain the result to a regulator.
The contenders:
- Markowitz Mean-Variance Optimization — the Nobel Prize–winning framework from 1952
- Black-Litterman — Goldman Sachs's 1992 fix for Markowitz's practical problems
- Rule-based — fixed target allocation with threshold rebalancing
- Equal-weight (1/N) — the naive benchmark that optimization should beat
The result surprised me. Not because rule-based won — I expected that. But because the margin wasn't even close.
The Setup
Four ETFs covering the core asset classes a European Robo-Advisor would use:
| ETF | Role | Inception |
|---|---|---|
| SPY | US Large Cap (S&P 500) | 1993 |
| EEM | Emerging Markets | 2003 |
| AGG | US Aggregate Bonds | 2003 |
| VNQ | US REITs | 2004 |
This benchmark intentionally uses a small, representative ETF set typical of retail robo-advisor core allocations. Larger universes increase the number of covariance parameters to estimate — a 20-asset portfolio requires estimating 210 unique covariance entries versus 10 for four assets — which is known to exacerbate estimation error in mean-variance frameworks.
Period: September 2004 to December 2024. 5,097 trading days covering the pre-crisis bull run, the Global Financial Crisis, the post-GFC recovery, COVID, and the 2022 rate hiking cycle.
All methods operate under the same constraints: long-only, maximum 60% in any single asset, identical data, no lookahead bias.
The rule-based strategy uses a "Balanced Growth" target of 60% SPY / 15% EEM / 20% AGG / 5% VNQ. This isn't an arbitrary split — it mirrors how retail robo-advisors structure portfolios in practice. Clients select from predefined risk profiles (conservative, balanced, growth) that define long-term strategic asset weights. These weights typically change only when the client's risk category changes, not dynamically based on short-term covariance estimates. The benchmark tests the operational question: does tactical optimization add value over strategic discipline?
The rule-based portfolio checks quarterly whether any asset has drifted more than ±5% from target. If it has, it rebalances. If not, it does nothing.
Markowitz and Black-Litterman reoptimize monthly using a 3-year rolling window for covariance estimation.
The full implementation is open-source: github.com/ferderer/portfolio-construction-benchmark
This is not a purely theoretical exercise. Public documentation from major robo-advisory providers suggests a strong preference for strategic asset allocation combined with automated threshold-based rebalancing rather than frequent tactical optimization. For instance, Vanguard Digital Advisor describes portfolio management centered on long-term strategic allocations with drift-triggered rebalancing. Scalable Capital's early positioning emphasized VaR-based dynamic allocation, while more recent product designs appear closer to strategic allocation frameworks. Many European white-label wealth platforms serving cooperative banks similarly rely on predefined risk profiles and minimal tactical overlay. While approaches differ across providers, there appears to be a practical convergence toward simplicity, scalability, and explainability in retail portfolio construction. This benchmark explores the potential economic drivers of that design pattern.
The Constraints Are the Requirements
Before diving into results, I want to reframe the problem. The standard framing is: "We want to optimize returns, but we're constrained by regulation, explainability, and operational complexity." This implies that constraints reduce performance — that we'd do better without them.
The data says otherwise.
A platform serving 400,000 retail clients across 875 white-label tenants needs portfolio construction that is:
- Auditable — BaFin can review the decision logic
- Explainable — "70% equities, 30% bonds" beats "the covariance matrix implied..."
- Scalable — no per-portfolio optimization at rebalancing time
- Compliant — MiFID II suitability assessments require transparent reasoning
- Cost-efficient — low turnover = low transaction costs at scale
In retail portfolio management, the constraints are not obstacles to optimization — they define what optimal means. The right question isn't "which model produces the best Sharpe ratio?" It's "which model meets all production requirements while delivering competitive returns?"
Markowitz: Correct Math, Wrong Problem
Harry Markowitz's insight was beautifully simple: don't just pick good assets — pick assets that are good together. By modeling expected returns and the covariance structure between assets, you can find the portfolio that delivers maximum return for any given level of risk.
The math works. The inputs don't.
Mean-variance optimization requires two inputs: a vector of expected returns and a covariance matrix. Both must be estimated from historical data. And the optimizer is exquisitely sensitive to estimation errors. Small changes in the covariance matrix — the kind you get from adding or removing a few months of data — produce wildly different "optimal" portfolios.
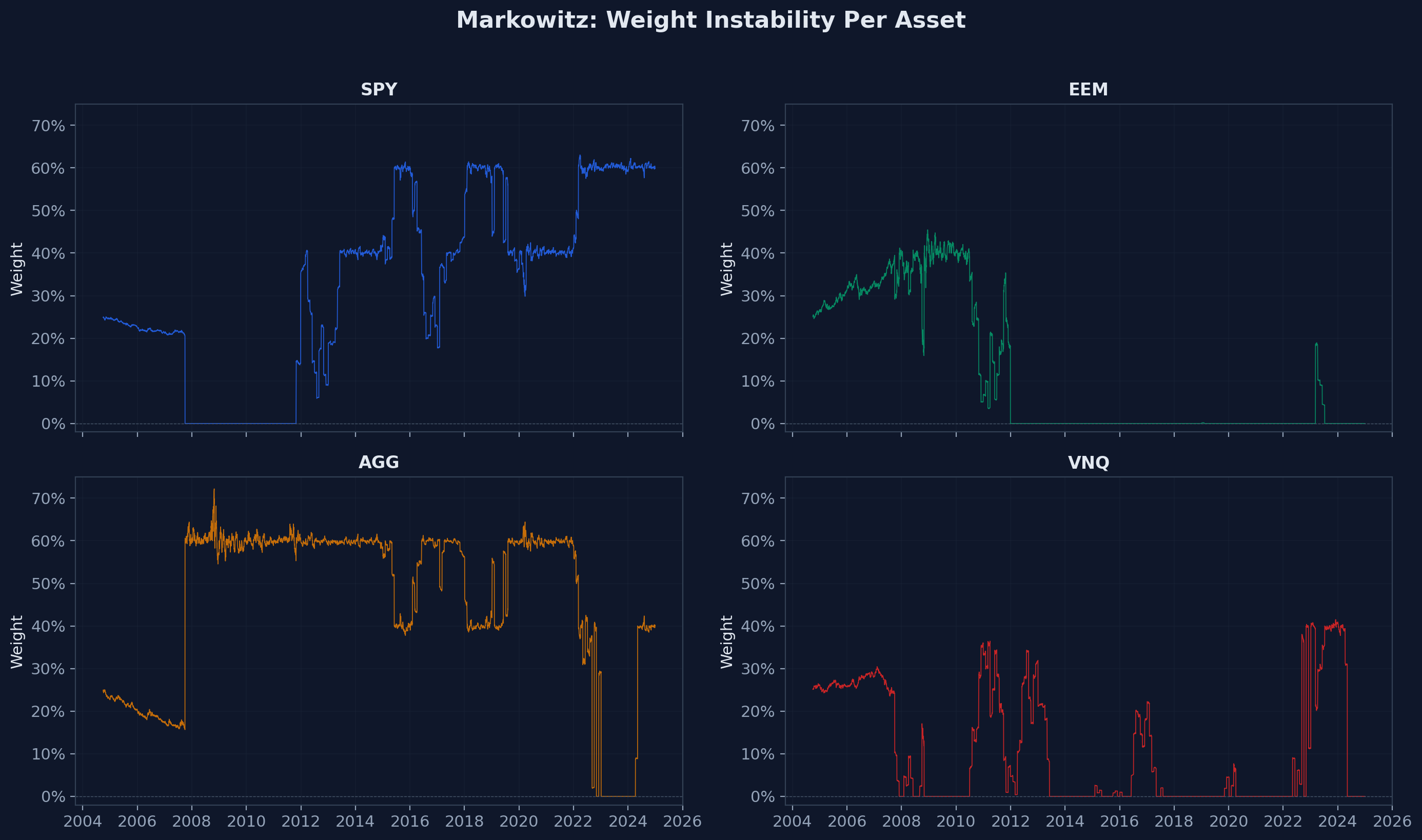
In this benchmark, Markowitz does exactly what it is designed to do. It concentrates the portfolio into the two assets with the best estimated risk-return profile and drops everything else. In recent years, that means ~60% SPY, ~40% AGG, and precisely 0% in both EEM and VNQ.
The actual weight ranges the optimizer produced over 20 years:
| Asset | Min Allocation | Max Allocation |
|---|---|---|
| SPY | 0.0% | 63.0% |
| EEM | 0.0% | 45.5% |
| AGG | 0.0% | 72.2% |
| VNQ | 0.0% | 41.5% |
Every asset swung between 0% and its maximum at some point. Every swing is a trade. Every trade costs money.
This concentration is not a bug in the optimizer — it's a feature. Markowitz is doing exactly what its objective function tells it to: maximize risk-adjusted return given the inputs. The problem is mandate mismatch. A "Balanced Growth" client profile that promises diversified exposure to equities, bonds, emerging markets, and real estate cannot deliver 0% Emerging Markets and 0% REITs. The optimizer solved the wrong problem.
Modern iterations attempt to fix the instability: Ledoit-Wolf shrinkage regularizes the covariance matrix, Hierarchical Risk Parity (HRP) bypasses the need for return estimates entirely, and minimum-variance portfolios remove the expected return input altogether. These are real improvements. But they address the estimation error problem while leaving the mandate drift and turnover cost problems intact. A shrunk covariance matrix still produces allocations that drift from the client's risk profile. An HRP portfolio still rebalances more frequently than a threshold-based approach. DeMiguel et al. (2009) found that even with these improvements, 1/N diversification remained competitive out of sample across most datasets.
Black-Litterman: Complexity Without Edge
Fischer Black and Robert Litterman published their model at Goldman Sachs in 1992 to solve exactly the problems above. Instead of feeding raw historical estimates into the optimizer, Black-Litterman starts from market equilibrium — the implied expected returns that make current market-cap weights optimal. This is a much more stable starting point than raw sample means.
Then you overlay "views" — quantified beliefs about which assets will outperform or underperform. The model blends these with the equilibrium prior, weighted by your confidence in each view.
It's elegant. It's theoretically sound. And it raises an immediate practical question: whose views?
For a hedge fund with a macro research team, the answer is obvious. For a Robo-Advisor serving 400,000 retail clients, it's not. You can't use the client's views. You can't use a committee's views at scale. So you automate the views, which is what I did here using momentum signals.
The implementation uses dampened 12-month momentum with several guards against overreaction: a confidence factor of 0.25, a ±15% annualized cap, volatility-scaled uncertainty, and relative views when the momentum spread between best and worst assets exceeds 8%. I tested multiple parameterizations — different lookback windows, confidence levels, and caps. While performance varied, none produced a consistent improvement over the rule-based strategy after transaction costs.
This highlights the core issue: in this no-edge automated implementation, the momentum views introduced instability rather than alpha — pushing the portfolio to 23% annualized volatility (vs. 16% for rule-based) without compensating returns. The elevated volatility stems from frequent weight rotations between the strongest and weakest momentum assets, amplifying exposure to already volatile segments like Emerging Markets and REITs.
An important distinction: Black-Litterman's primary value in a retail context is usually Strategic Asset Allocation (SAA) — using the equilibrium prior to produce a stable, diversified baseline without active views. The problems in this benchmark emerge from using it for Tactical Asset Allocation (TAA) via momentum signals, which is where the noise entered. A pure-prior BL without views would produce allocations close to market-cap weights — reasonable, but then you're paying for the machinery of the model while getting a result you could hardcode in a config file.
Black-Litterman is a powerful framework when fed genuine predictive views from a dedicated research process. In a retail robo context without proprietary signals, it collapses into expensive noise.
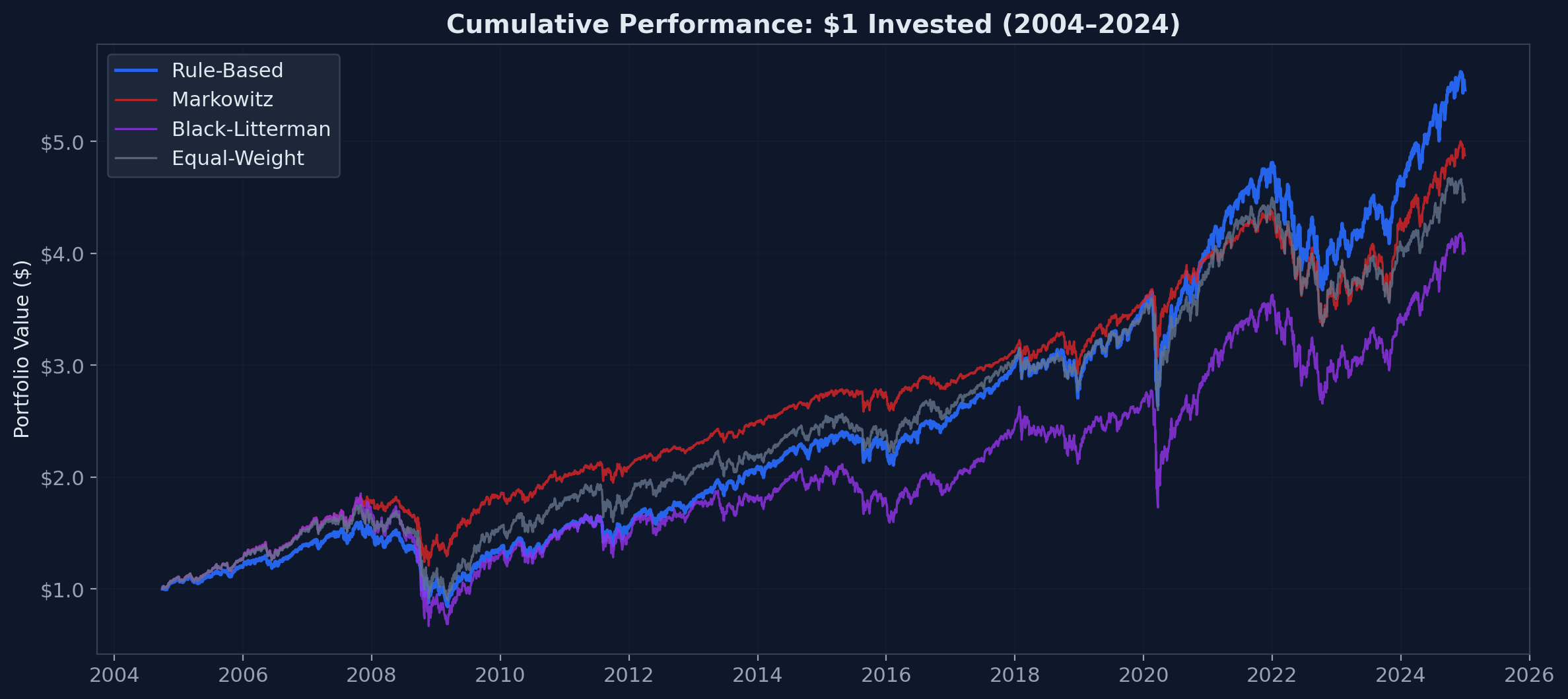
The Numbers
| Rule-Based | Markowitz | Black-Litterman | Equal-Weight | |
|---|---|---|---|---|
| CAGR | 8.76% | 8.15% | 7.12% | 7.70% |
| Volatility | 15.89% | 11.83% | 23.27% | 16.77% |
| Sharpe Ratio | 0.425 | 0.520 | 0.220 | 0.340 |
| Max Drawdown | 47.41% | 33.99% | 63.94% | 48.58% |
| Annual Turnover | 101.91% | 223.36% | 236.38% | 152.21% |
| Rebalance Count | 211 | 677 | 501 | 445 |
| Tracking Error* | 0.95% | 7.45% | 8.70% | 4.10% |
*Tracking error — the annualized standard deviation of daily return differences — measures how far a portfolio drifts from its intended allocation. Measured here vs. a daily-rebalanced 60/15/20/5 target. Rule-based has low tracking error by construction — its target is the benchmark. For Markowitz and Black-Litterman, tracking error captures how far the optimizer drifts from the client's promised allocation.
Read that table carefully. Markowitz has the best Sharpe ratio. If you stopped there, you'd pick Markowitz. But the Sharpe advantage comes entirely from lower volatility — which comes entirely from concentrating the portfolio into two assets. That's optimization working as designed. It's also incompatible with the client mandate. If the mandate were simply "maximize Sharpe ratio," Markowitz would win. But retail mandates are defined by strategic allocation categories — equities, bonds, emerging markets, real estate — not abstract risk-return objectives.
The 1/N equal-weight benchmark is instructive. At 7.70% CAGR with no optimization whatsoever, it outperforms Black-Litterman (7.12%) and nearly matches Markowitz (8.15%) — while requiring no covariance estimation, no views, and no rolling windows. This echoes DeMiguel et al. (2009), who showed that naive diversification outperforms most optimization strategies out of sample. Note that equal-weight still trades more than rule-based (152% vs. 102% turnover) because it rebalances all four assets back to 25% at every trigger, whereas the threshold approach often does nothing — most quarters, no asset has drifted far enough to trigger a trade.
The tracking error tells the operational story. Rule-based stays within 0.95% of its target allocation. Markowitz drifts 7.45% away. The Markowitz portfolio bears almost no resemblance to what was promised to the client.
What Transaction Costs Reveal
Running all strategies at 0, 10, and 20 basis points of transaction costs exposes the operational cost of complexity:
| Strategy | 0 bps | 10 bps | 20 bps | CAGR Drag |
|---|---|---|---|---|
| Rule-Based | 8.76% | 8.75% | 8.74% | −0.01 pp |
| Markowitz | 8.15% | 8.03% | 7.92% | −0.23 pp |
| Black-Litterman | 7.12% | 6.98% | 6.84% | −0.28 pp |
| Equal-Weight | 7.70% | 7.69% | 7.68% | −0.02 pp |
Rule-based loses 1 basis point to transaction costs over 20 years. Markowitz loses 23. Markowitz loses 23 times more to transaction costs than rule-based.
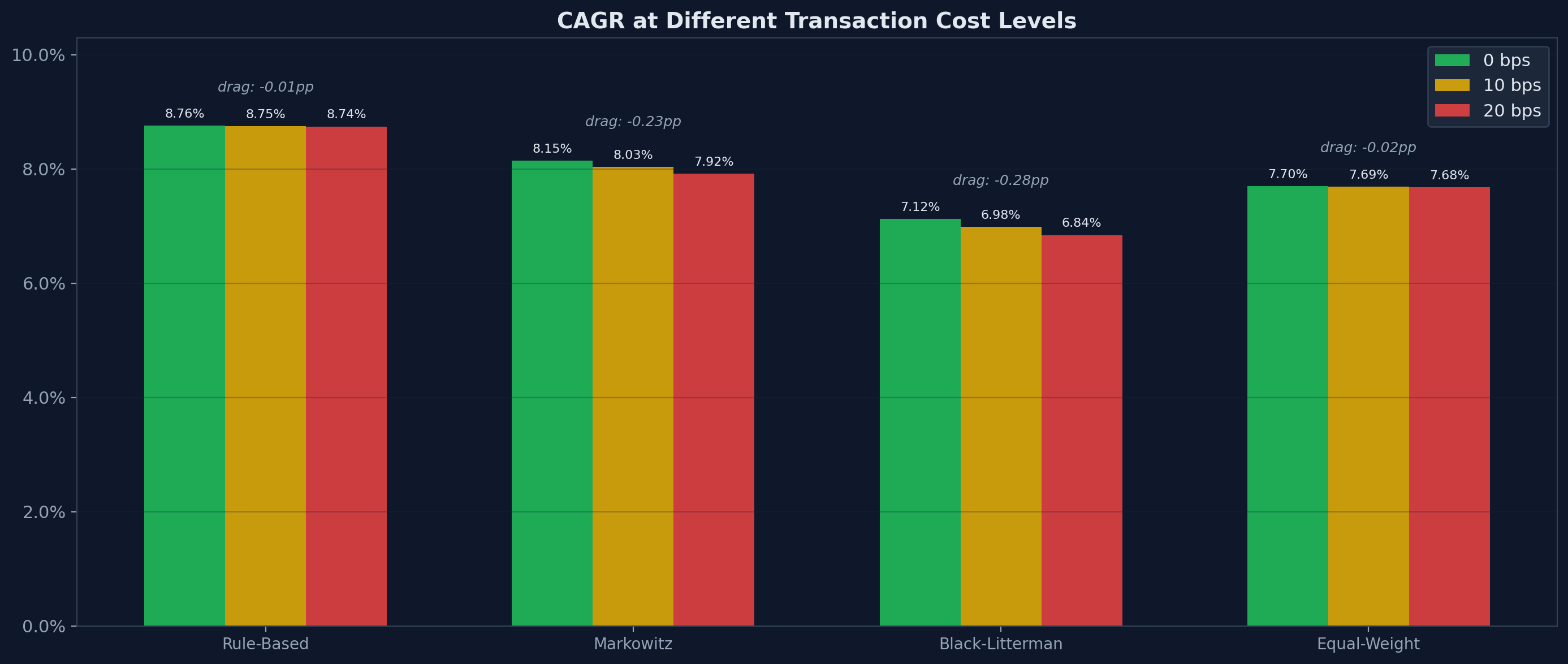
At 20 basis points — a conservative estimate for ETF trading — that's the difference between 8.74% and 7.92% CAGR. Compounded over 20 years on a €100,000 portfolio, that's roughly €16,000 in lost returns. Not because the underlying investments performed differently, but because the optimizer traded too much. And this understates the real cost: in taxable accounts, every rebalancing trade can realize capital gains. Over a 20-year horizon, the tax drag of frequent re-optimization often exceeds the explicit transaction costs.
Robustness
A fair objection: maybe the 60/15/20/5 allocation just happened to work well in this period. If the result depends on one specific target, the conclusion is fragile.
It doesn't. Varying the rule-based equity allocation between 50% and 70% does not change the ranking:
| Rule-Based Variant | CAGR | Sharpe | Max Drawdown | Turnover |
|---|---|---|---|---|
| 60/15/20/5 (default) | 8.76% | 0.425 | 47.41% | 102% |
| 70/10/15/5 (aggressive) | 9.35% | 0.440 | 48.93% | 81% |
| 50/20/25/5 (moderate) | 8.16% | 0.404 | 45.19% | 119% |
All three rule-based variants outperform Black-Litterman in CAGR. The aggressive variant outperforms every strategy on every metric except max drawdown. The moderate variant, with less US equity exposure, still beats Markowitz in CAGR while maintaining lower turnover.
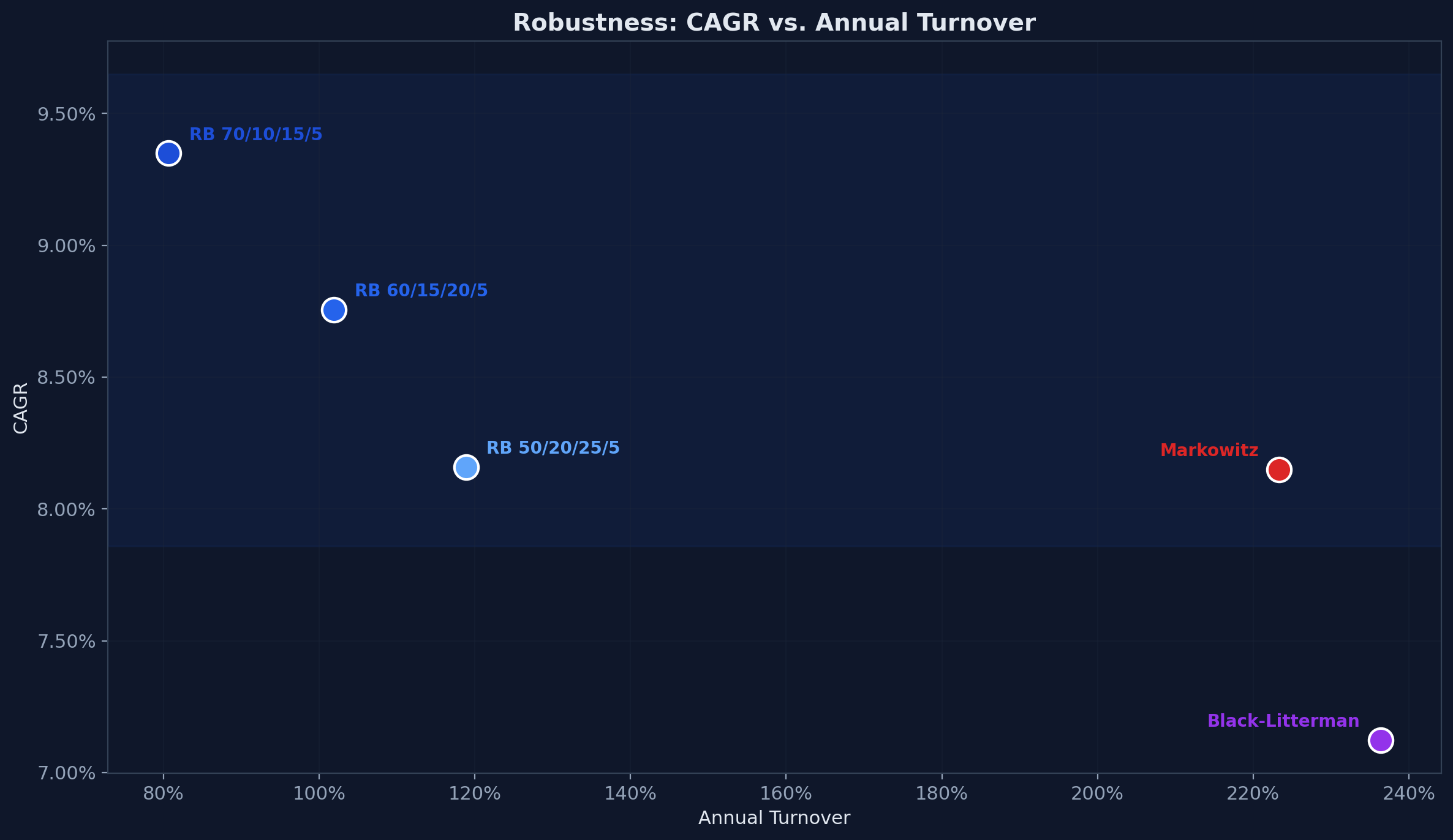
The pattern is stable. The specific weights matter less than the approach.
Rebalancing frequency and threshold sensitivity reinforce this further. Trading less never hurts:
| Rebalancing Config | CAGR | Turnover | Rebalances |
|---|---|---|---|
| Monthly, ±3% | 8.75% | 103% | 220 |
| Quarterly, ±5% (default) | 8.76% | 102% | 211 |
| Semi-annual, ±10% | 9.36% | 98% | 178 |
Checking less frequently with wider thresholds reduces turnover and rebalancing events while maintaining — or even improving — CAGR. The semi-annual variant checks half as often, tolerates twice the drift, trades less, and delivers the highest return of any configuration tested. In this period, trading less did not hurt — and in some configurations improved outcomes.
When to Use What
This is not an argument against Markowitz or Black-Litterman. It's an argument against using them where they don't belong.
Use rule-based when you serve retail clients at scale, regulatory compliance requires explainable decisions, your edge is in product and distribution rather than alpha generation, and you need to audit every allocation decision.
Use Markowitz when you can guarantee the quality and stability of your input estimates, you enforce minimum weights per asset to prevent pathological concentration, and your rebalancing frequency is low enough that turnover stays manageable.
Use Black-Litterman when you have access to genuine, quantifiable views with demonstrated predictive power — views that survive the round trip through the model, the optimizer, and the transaction costs of acting on the result.
For most Robo-Advisors, that means rule-based. Not because it's the only viable option — but because the conditions that make the alternatives worthwhile rarely exist in retail wealth management.
Reproducing These Results
git clone https://github.com/ferderer/portfolio-construction-benchmark.git
cd portfolio-construction-benchmark
python -m venv .venv && source .venv/bin/activate
pip install -e .
python -m src.data_loader # download ETF data
python -m scripts.run_benchmark # run all strategies + transaction costs
python -m src.visualize # generate chartsAll parameters are function arguments — adjust allocation targets, rebalancing thresholds, lookback windows, transaction costs, and view confidence to test your own assumptions. Each strategy is a single file under 120 lines.
For financial terms used in the article, see GLOSSARY.md.
References
- Markowitz, H. (1952). Portfolio Selection. The Journal of Finance, 7(1), 77–91.
- Black, F., & Litterman, R. (1992). Global Portfolio Optimization. Financial Analysts Journal, 48(5), 28–43.
- DeMiguel, V., Garlappi, L., & Uppal, R. (2009). Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy? The Review of Financial Studies, 22(5), 1915–1953.
- Directive 2014/65/EU (MiFID II), European Parliament and Council.